Several Unregistered Comms Beacons that are part of a mystery, which can be found in orbit of the following core worlds:
- Sol – Europa
- Achenar – Capitol
- Gateway 2
Each of the beacons are identical, and are known to transmit the following every hour, on the hour:
(Note: was previously, every hour at 40 minutes past)
12 9 19 20 5 14
12 15 3 1 20 9 15 14
5 18 1 22 1 20 5
20 9 13 5
10
12 9 19 20 5 14
12 15 3 1 20 9 15 14
12 1 22 5
20 9 13 5
30
3 12 21 5
4 C
(repeated four times)
Decodes by letter positions, and with some lateral thinking, to:
- LISTEN LOCATION ERAVATE TIME 10
- LISTEN LOCATION LAVE TIME 30
- CLUE 4 C
Note that the times given are incorrect, and need to be swapped.
An Unregistered Comms Beacon can be found in orbit of Eravate 5, and is known to transmit the following at 30 minutes past every hour:
X
0
6
1 1 1
1 1
1 1 1 1
1 1 1
1 1
1 1 1 1
6
1
1 1 1
1 1 1 1 1
0
1 1 1
5
1 1 1
1 1 1
1 1 1 1 1 1 1
1 1 1
1 1 1
5 1 1
1
1 1
1
5 1 1
1 1 1
1 1 1 1
1 1 1
1 1 1
1 1 1
5
1
0
1
5
1 1 1
1 1 1
1 1 1 1
1 1 1
1 1 1
5
1
0
3
1 1
1 1 1 1 1 1
1 1
3
0
1
5
1 1 1
1 1 1
1 1 1 1 1 1 1 1
1 1 1
1 1 1
5
1
0
5
1 1
1 1
1 1 1 1 1 1 1 1
1 1
1 1
5
0
1
3
1 1 1
1 1 1
1 1 1
3
1
0
(repeated two times)
Another Unregistered Comms Beacon can be found in orbit of Lave 2, and is known to transmit the following at 10 minutes past every hour:
Y
0
6
1 1 1 5 5 5 5 5
1 1 1 1 1 1 1 1 1 3 1 1 1 1 3
1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
1 1 9 9 9 1 1 9 1 1 7
1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 3 1 1 1 1 3
6 1 5 5 5 5 5
0
1 1 1 1 1
0
1 1 1 1
0
1 1 1 1
0
1 1 1
1 1 1 1 1 1
1 1
1 1 1 1
1
1 1 1 1 1 1 1 1 1
(repeated two times)
Together these messages describe the horizontal (X) and vertical (Y) components of a nonogram.
A complete solution is not possible with the data from the two beacons, however the solvable part draws an image of a system map:

The unsolvable nonogram was recognized as an error and two additional Unregistered Comms Beacons placed in order to allow the puzzle to be solved.
The first appeared in orbit of Col 285 Sector IX-T d3-43 A 1, directly outside the Cannon Institute, and transmitted the following at 20 minutes past every hour:
(Note: This Unregistered Comms Beacons has been removed.)
19 13 1 12 12 19 29 5 16
7 9 1 14 20 12 5 1 16
30
4 15 14 13 6 15 12 12 15 23 19
(repeated three times)
Decoded by letter positions, and other ASCII codes, to:
SMALLS?EP
GIANTLEAP
30
DONMFOLLOWS
This provided a clue to the Moon, which is where a second Unregistered Comms Beacon can be found in orbit, known to transmit the following, every hour at 44 minutes past:
(Note: was previously, every hour at 30 minutes past)
12 5 20 18 1 14 19 11 5 25 20 15 21 3 8
R1 0
R2 C5 C7 C11 C13 C22 C24
R3 0
R4 C4 C13 C20 C22
R5 0
R6 C2 C4 C7 C9 C11 C17 C20 C24 C26
(repeated three times)
- The initial sequence of numbers decodes to the word LETRANSKEYTOUCH by letter positions.
- “Le Trans Key Touch” is a clue that the key to translating the image is related to French and Touch: Braille.
- The following data provides row and column co-ordinates to fill-in the unsolvable part of the nonogram:
- Rows in the unsolvable part are numbered 1–6;
- A row with no blocks to be filled is given as 0;
- Otherwise the column numbers to be filled are given.

Ignoring the irregular dot spacing, this gives us the following Braille text:
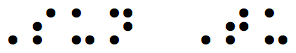
Which translates as “Sun Tu”. The system matching the image described in the nonogram, and closest to this in name, is “San Tu”.

Combined with the “Clue 4 C” from the originating beacons for this quest, this lead to the San Tu Scientific Installation where the mystery continued.










